


Embeddings
An embedding is simply an array of numbers that captures the semantic meaning of the input text.
> "Semantic embeddings are a powerful technique in natural language processing (NLP) that transform words, sentences, or entire documents into numerical vectors, capturing their meaning and relationships in a high-dimensional space" (Perplexity.ai)
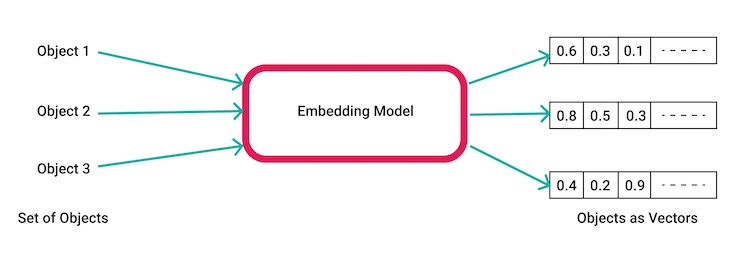
Anyone familiar with large language models may already understand embeddings. An embedding is simply an array of numbers that captures the semantic meaning of the input text.
The input data could be anything, for example:
A word: "Hello".
Or a sentence: "Hello, how are you today?"
Or an entire paragraph of text.
The input data goes into the embedding model (a specialized kind of neural network), and what comes out is the embedding, which is an array of numbers.
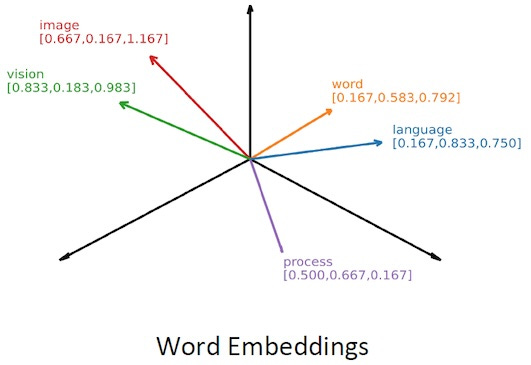
Key: Think of that array of numbers as a point in space: [X,Y,Z]
An embedding is actually a point in a high-dimensional space (like with 12,000 dimensions), so it's not just 3 dimensions. However, it's still useful to visualize a 3D space.
KEY UNDERSTANDINGS:
1. If you draw a line from [0,0,0] to [X,Y,Z], that line points out a direction in space, and that direction captures the semantic meaning of the input data.
2. ==> You can add and subtract these embeddings to affect the meaning!! <==
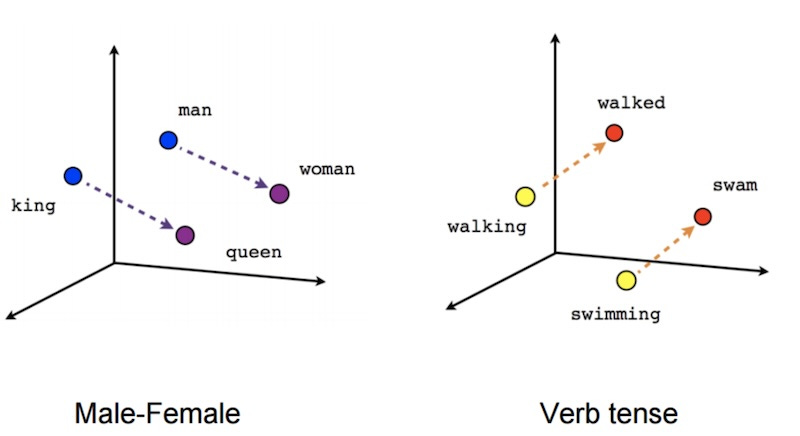
Here's the magic example:
If you take the word "Hitler" and put it through an embedding model, the output consists of an array of 12,000 numbers – that is, a direction in a high-dimensional space – that somehow magically captures the semantic meaning of the word "Hitler".
Then if you take the word "Germany" and put it through the same embedding model, you will get another embedding. Another array of 12,000 numbers.
And remember, you can add and subtract these embeddings from each other.
So, if you take the embedding for the word "Hitler" and then subtract the embedding for the word "Germany", and then add the embedding for the word "Italy”, you will end up with an embedding that is very close in the high dimensional space to the embedding for the word "Mussolini”.
Get it? That's the key understanding.
Nearest Neighbor (Similarity Search)
We don't normally search an embeddings database for an exact match. Instead, we search for the "nearest neighbors" that are most near to the meaning we're searching for. (That's called "K Nearest Neighbor").
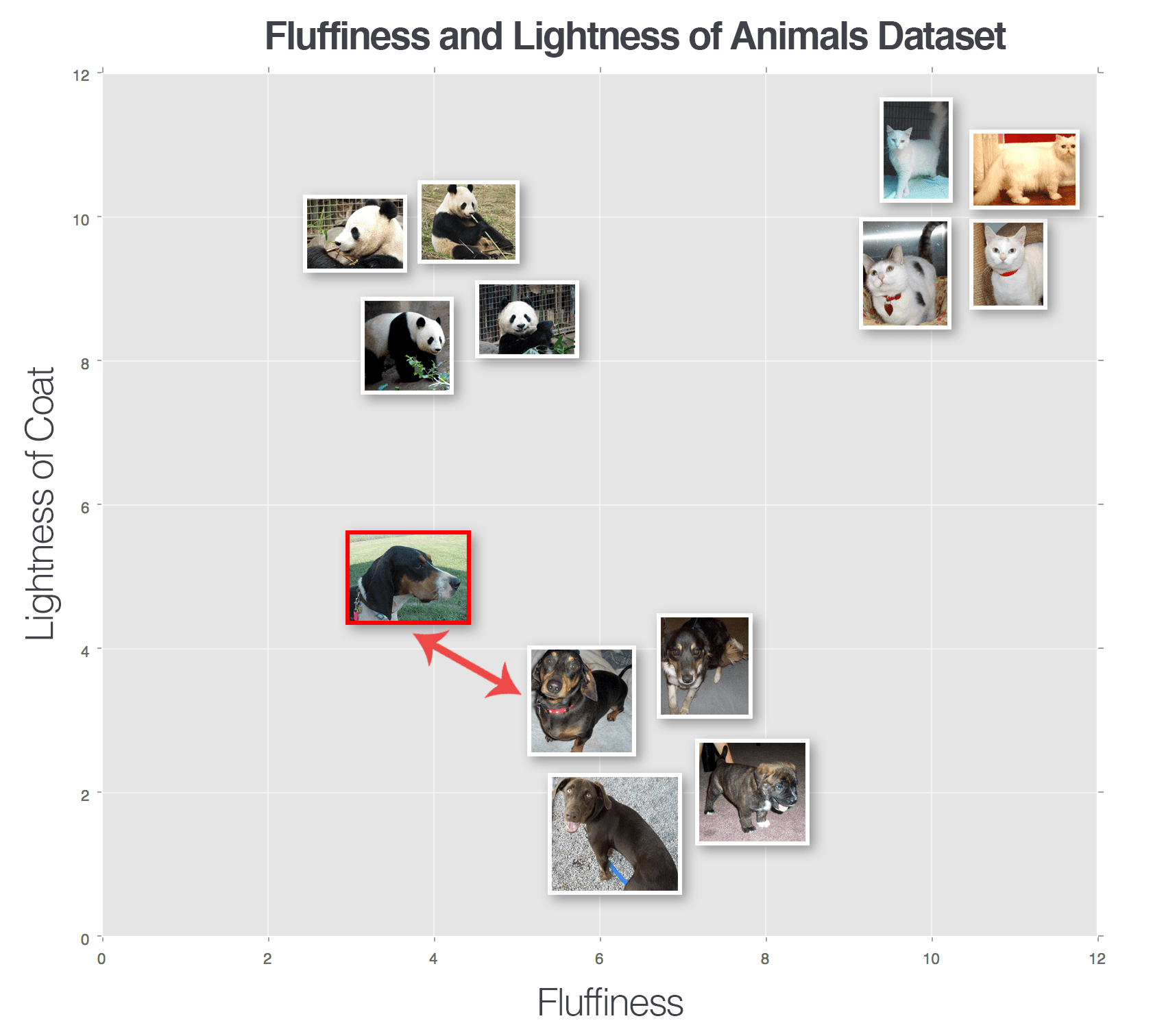
When we search a given photo (which depicts a dog, in this case), then we want it to be found in the high-dimensional embedding space to be near a cluster of other dog pictures. Because if the 5 nearest neighbors are all dogs, then we probably have a picture of a dog. So, now the AI can tell you: "This picture shows a dog." Even if the AI has never seen that specific dog picture before. Makes sense?
Unstructured Data
Our artificial intelligence "mind" receives input data as experiences, which are purely unstructured data, and these episodes are recorded in various modalities.
When I say "unstructured data", consider that a piece of text like the sentence "Jane comes from Colorado" is simply a string of characters, nothing more, nothing less. So, the raw input data would therefore be recorded as that string of characters.
However, it's possible to extract structured data from that input. Facts such as the entity Jane, the entity Colorado, and the relationship between them. That's what brings us to knowledge graphs…