
Knowledge Graphs
Knowledge graphs are stored as triplets representing entities and relationships.
> "Knowledge graphs are sophisticated data structures that represent information as interconnected networks of entities and their relationships. This powerful approach to organizing information mirrors how humans naturally understand and connect concepts.” (Perplexity.ai)
Consider this piece of text:
I'm Christopher. My mother and father met in Los Angeles, the city where I was born. My mom's family came from Missouri originally, and my dad's family came from Louisiana, though both trace their ancestry back to Europe. My mom's name is Nancy, and my dad's name is David, and I have two sons, Thomas and Jacob, and a daughter, Isla James.
An LLM can be used to extract these triplets from the text:
(Nancy, married, David)
(Nancy, from, Missouri)
(David, from, Louisiana)
(Nancy, ancestry from, Europe)
(David, ancestry from, Europe)
(Nancy, met David in, Los Angeles)
(Christopher, mother is, Nancy)
(Christopher, father is, David)
(Christopher, born in, Los Angeles)
(Christopher, has son, Thomas)
(Christopher, has son, Jacob)
(Christopher, has daughter, Isla James)
These triplets can then be stored in a knowledge graph, which is a kind of database that stores entities and relationships.
Like this:
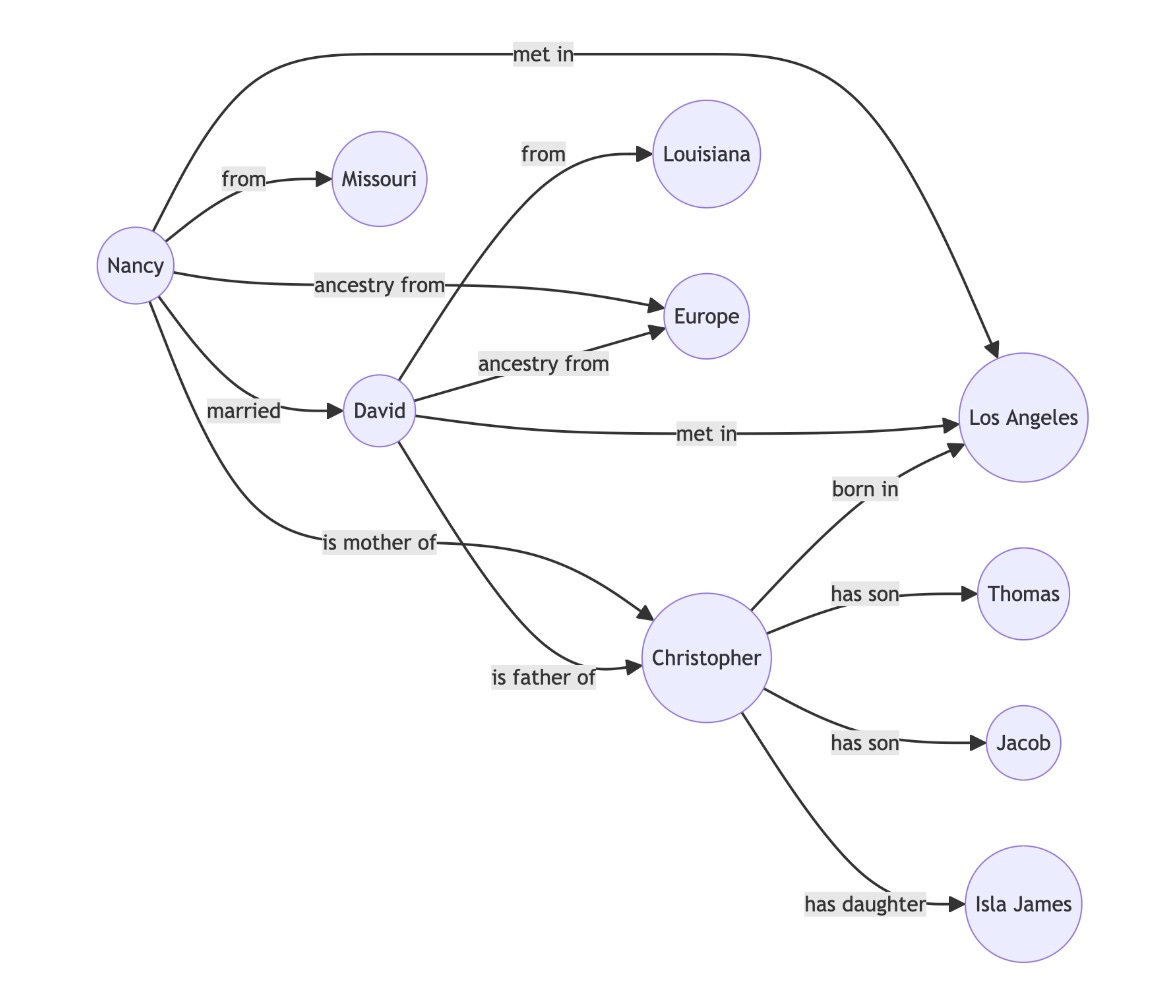
Let's not get distracted
There is a lot of computer science around knowledge graphs…
What ontology should be used?
What are the best practices for storage and retrieval?
What is the best way to organize the knowledge?
How can we reduce computational load?
How can we do entity resolution in order to de-duplicate nodes in the database?
Etc. (But that's not important right now).
What matters is understanding that the knowledge graph captures structured knowledge about entities and their relationships, enabling us to reason about that knowledge.

Retrieval
Returning to our original piece of input text:
I'm Christopher. My mother and father met in Los Angeles, the city where I was born. My mom's family came from Missouri originally, and my dad's family came from Louisiana, though both trace their ancestry back to Europe. My mom's name is Nancy, and my dad's name is David, and I have two sons, Thomas and Jacob, and a daughter, Isla James.
Once we've extracted the triplets from that text using an LLM, we can store that knowledge in structured form, which enables us to do useful reasoning about it.
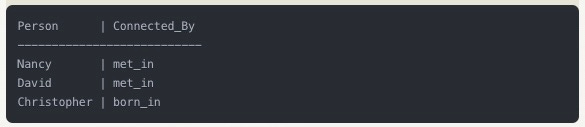
Using the Cypher query language, let say we wanted to find all family members who were connected to Los Angeles in any way:

That would return:
Now let's trace from each child, through Christopher, back to their grandparents, and show where each person in that lineage originated from. This demonstrates how we can hop through family relationships while also collecting geographic information along the way.
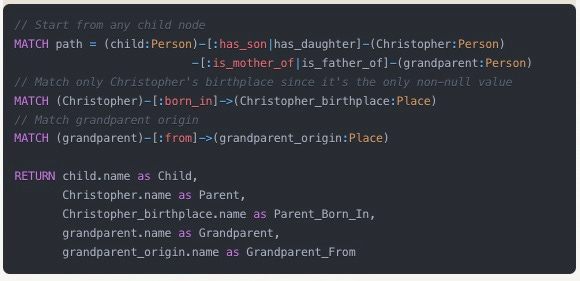
Output:
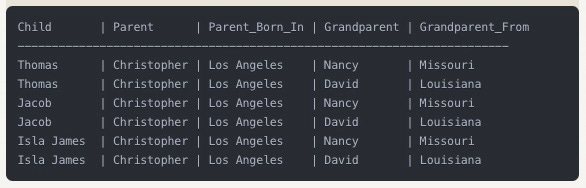
The power of this multi-hop query is that it's tracing:
Forward in time (from grandparents to children)
Across different types of relationships (both family connections and geographic origins)
Through multiple generations (spanning three levels of family members)
Each child appears twice because they connect to both grandparents (through Christopher)
You get the point.