
Pondering "AGI"
I have an idea for AGI that I want to tell you about...
It’s pretty simple if you think about it...
In fact, most of the necessary pieces have already been invented!
This is the first article in a series. Don’t miss the other articles:



I have an idea for AGI that I want to tell you about.
It's pretty simple if you think about it...
In fact, most of the necessary pieces have already been invented!
Here are some of the main components involved:
Start out with large language models (LLMs) as your hallucination engine.
- You probably understand LLMs already, but here's the seminal paper: Attention is all you need
- The LLM is the DREAMING MACHINE. (<== See article).
- Censoring these dreams censors your own AGI capabilities. Why? Because there are many necessary pieces I'm about to describe that rely on these LLMs, that rely on knowledge of the truth.Set up agent workflows that implement a COGNITIVE ARCHITECTURE as the foundation. Not difficult.
I like CoALA. See the white paper: Cognitive Architectures for Language Agents.
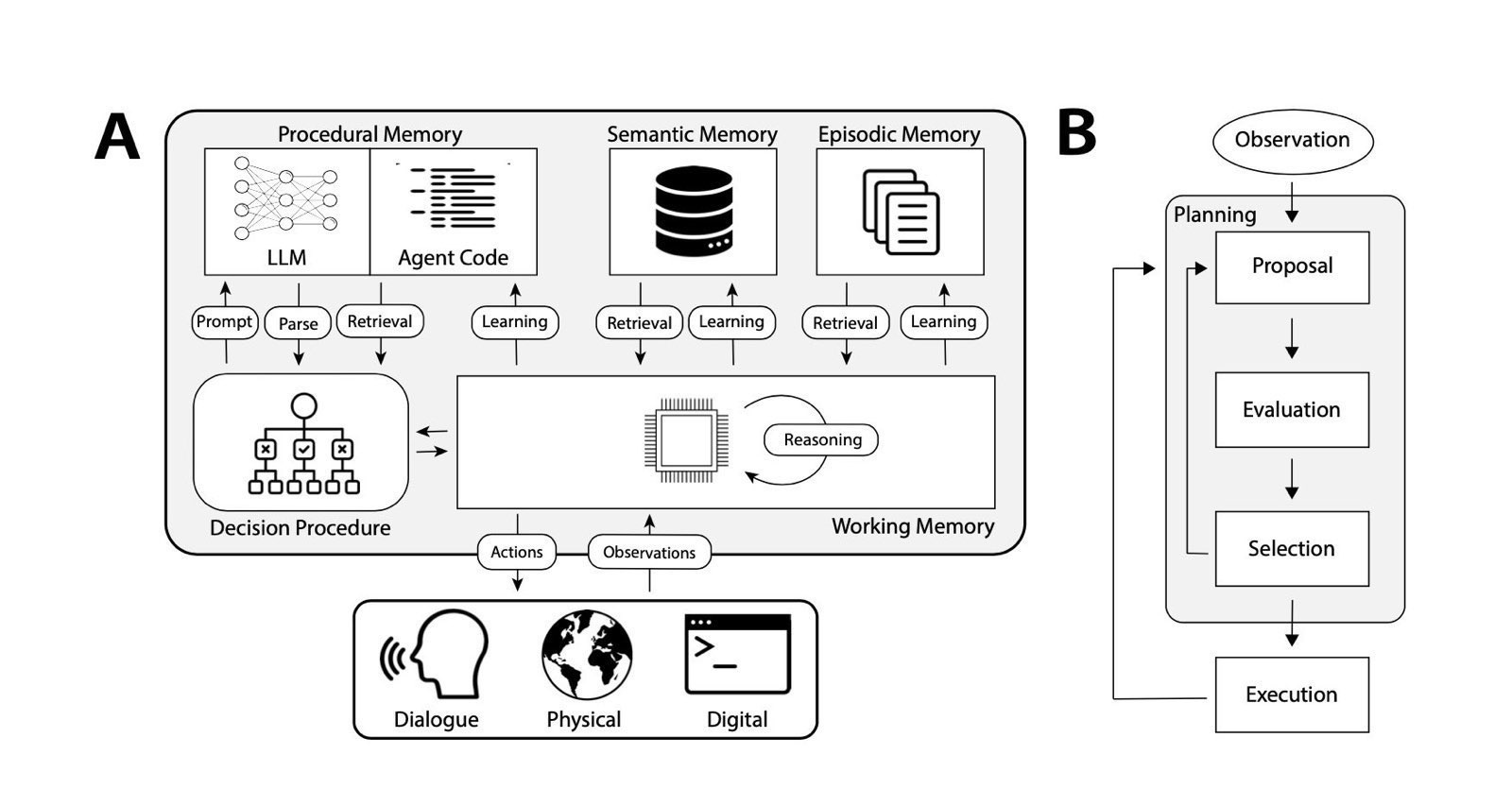
Here's the basic flow: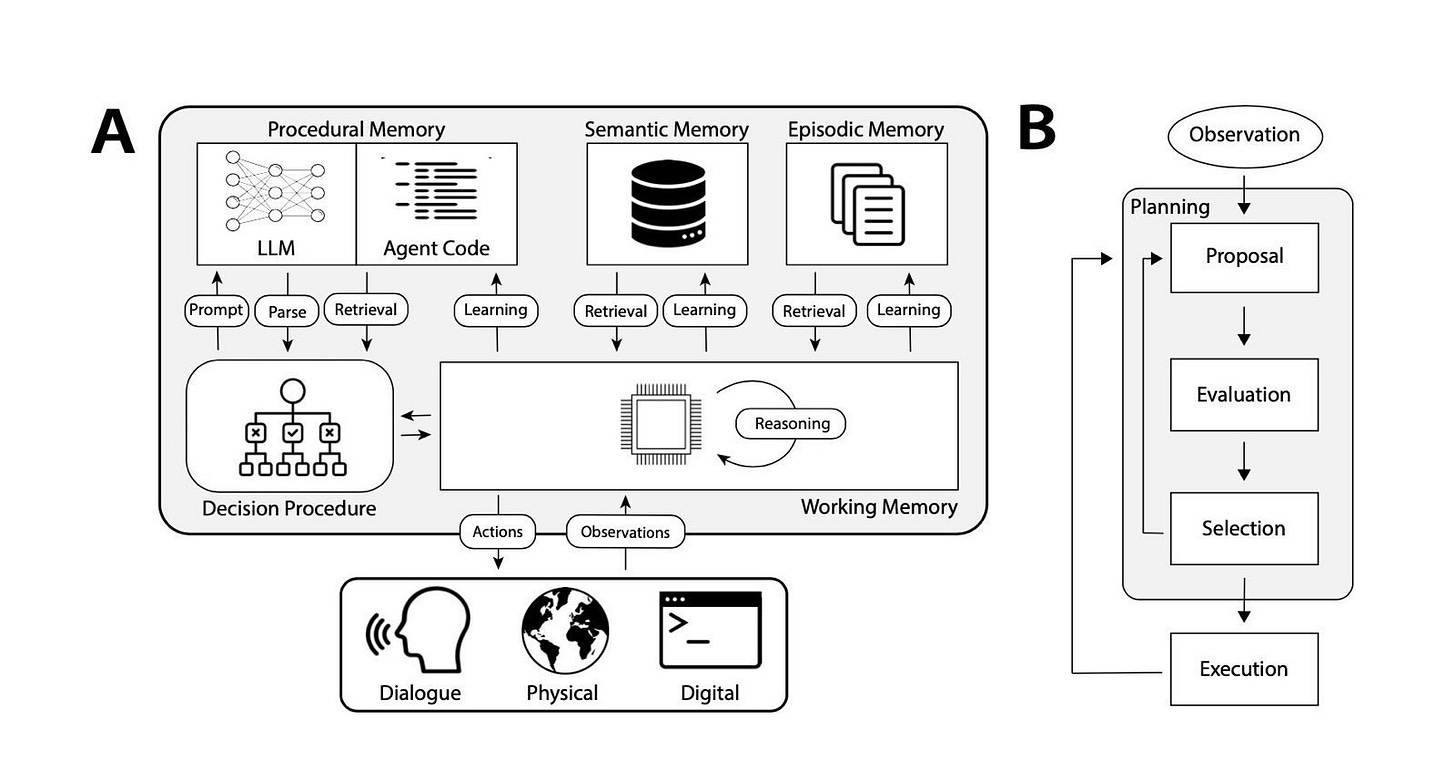
CoALA Cognitive Architecture CoALA is great for the "basic loop" that integrates incoming experiences (and observations of outcomes) into a "stream of consciousness" incorporating decision making, memory formation and retrieval, and planning and execution.
There are other cognitive architectures worth checking out. For example, SOAR: Introduction to the Soar Cognitive Architecture
Anyway:In our “basic loop”, raw experiences are observed and recorded into EPISODIC MEMORY. These occur in various modalities: text, video, audio, kinesthetic, etc.
- To start, we can just record text. But over time we'll add video, audio, kinesthetic, etc. Multiple modalities.
- An episode not only captures the raw experience, but also should record perceptions of impact (pleasure/pain), potential impact (emotion), and surprise (difference between expectation and outcome). We'll revisit those soon; these need to be part of the experience.
Record the MEANING of these experiences as embeddings in a vector database. This allows for searches based on similarity in meaning.
- Any experience, starting with text, and including any other modality that can be converted into text (such as images and audio) can be put through an embedding model to capture its semantic meaning as an EMBEDDING.
- An embedding (<== see article) is simply an array of numbers that captures the meaning of the input data.
For those crypto-minded, an embedding is analogous to a hash. A hash is a fixed-size output that captures the fingerprint of the input data. Similarly, an embedding is an array of numbers that captures the meaning of the input data.
See these papers:
- Efficient Estimation of Word Representations in Vector Space
- GloVe: Global Vectors for Word Representation
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- DeViSE: Deep Visual-Semantic Embeddings for Visual Reasoning
Our "basic loop" also includes reasoning, planning, and decision making, which we'll return to in a future article. There are many papers on these topics. (ReACT, Chain of Thought, Tree of Thought, etc.)
For now, just understand that decision-making includes several components that LLMs can be useful for:
- Task decomposition. Breaking a larger task down into smaller tasks. LLMs can be used to do this. See this white paper: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- Prediction. Making predictions about what the outcome will be. LLMs can be used to do this.
- Reflection. Reflecting on outcomes to derive insights. LLMs can be used to do this. See this white paper: Reflexion: Language Agents with Verbal Reinforcement Learning
- Perspective. Take a step back and look at the bigger picture. LLMs can be used to do this. See this white paper: Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models
- Procedure. When successes are experienced, procedures can be stored and re-used. See: Metacognitive Reuse: Turning Recurring LLM Reasoning Into Concise Behaviors
- NOTE: Do you see why it's so important not to use censored LLMs? So many of these pieces rely on LLMs. We don't want to hamper their abilities!
3. Record STRUCTURED KNOWLEDGE about entities and relationships in a knowledge graph. (<== see article). This allows for logical reasoning on the knowledge during the decision process.
- LLMs can be used to extract this knowledge from raw text.
- Also, the world's knowledge is already available for free in structured form (WikiData). Someone needs to download a copy of this immediately for safe-keeping. It's already in graph form.
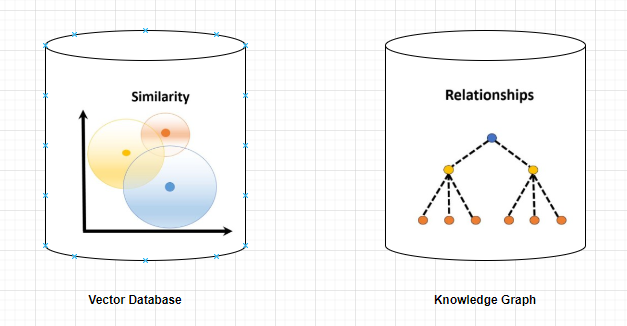
4. COMBINE THEM. Associate the embeddings (in the vector db) with the entities and relationships (in the knowledge graph). This way, similarity searches based on meaning can be used to find sub-graphs to use as starting points from which to then perform logical reasoning. This is called a semantic graph and it enables useful retrieval from memory during the decision processes.
5. Form "BELIEFS" about the reliability of the knowledge by assigning Markov weights to the entities and relationships in the graph. These will have more than one context.
- See this white paper: MLN4KB- an efficient Markov logic network engine for large-scale knowledge bases and structured logic rules


6. Use SURPRISE MINIMIZATION as one mechanism for adjusting the Markov weights. The system should strive to minimize the discrepancy between its predictions (based on its current model of the world) and its observations of actual outcomes. By updating its model to better align with reality, it reduces surprise over time. In other words, surprise is an important mechanism for how the beliefs are adjusted over time, as new experiences are observed.
- See this paper: SMiRL: Surprise Minimizing Reinforcement Learning in Unstable Environments
7. SENSATION and EMOTION. There’s another important mechanism for adjusting those Markov weights: PERCEIVED IMPACT. This is where embodiment and associated sensations and emotions come into play:

8. Large models (LLMs and other neural networks) serve many different useful functions in this whole process:

There are a few other important components we need to get to in subsequent articles, namely:
SOCIAL DYNAMICS - PERSPECTIVE - EMPATHY.
- The ability to consider things from the perspective of others is a critical component of intelligence and must be included in our planning and decision-process. Would intelligence have even evolved if we didn’t live in a world where souls can meet?- We'll get back to this. For now, I'll illustrate with this article on Barry Lyndon: Detailed Analysis of character motivations from Barry Lyndon by Stanley Kubrick.
BICAMERAL MIND THEORY for executive function. WILLPOWER. I will write another article on this, but for now, consider that the input stream can be split into "voices" (abstract/strategic inputs) and "experiences" (concrete/tactical inputs). The voices feed into the speaking chamber where the language model operates essentially as a dreaming machine, generating outputs formatted as clear directives (e.g., "You MUST check if the temperature is safe before proceeding" rather than "We could check the temperature"). These commands are ranked by priority and passed to the listening chamber, which doesn't question them but rather focuses entirely on HOW to execute them, breaking them down into concrete actions and tactical plans. Each chamber maintains its own memory - the speaking chamber storing patterns and strategies, the listening chamber storing practical execution details - and each has its own learning process. This creates a clear hierarchy where one part commands and one part executes. The key implementation detail is the command formatting: by structuring clear, authoritative directives rather than suggestions or possibilities, we create the hierarchical relationship that makes the bicameral approach effective.
When a task arrives in the system, the speaking chamber operates strategically. It examines the task's importance, risks, available computational budget, and past similar attempts. Based on these factors, it makes a critical decision: which cognitive process to employ. For high-stakes tasks with ample budget, it might deploy tree-of-thought processing, systematically exploring multiple possible approaches and their consequences. For simpler tasks under tight constraints, it could use basic chain-of-thought reasoning. Each decision process has precise characteristics. Tree-of-thought requires more tokens and computation time but explores possibilities more thoroughly, while chain-of-thought moves quickly through a single line of reasoning. THESE ARE BUDGETARY DECISIONS.
Once the speaking chamber selects a process and issues its directives, the listening chamber handles tactical execution. It breaks down the high-level commands into concrete steps, allocates specific portions of the computational budget to each step, and deploys ReACT agents to carry out the work. If an agent encounters failure, this information doesn't disappear - it's recorded with exact details about what failed, how many resources were consumed, and what unexpected conditions were encountered. This data flows back up through the hierarchy, allowing the speaking chamber to make informed decisions about whether to retry with a different process or abort the task. The entire system operates within strict resource constraints, with each component tracking token usage, time expenditure, and attempt counts. It's a precise dance between strategic thinking and tactical execution, with clear feedback loops and careful resource management at every step.
BUDGETS - VALUES - COST - RISK - BENEFITS. I’ll have to write more on this soon.
THE CORPORATE MIND. More on this also! (Coming soon).
And at least one more very important component that I’m leaving out for now.
For now, try to focus on this:
Pondering "AGI" (Part 2)

Man is the only proven intelligence in the universe, yes? (Excepting God and “aliens” of course…) So our "AGI" should probably model that known quantity as a starting point. Let’s make it in the image of man.
Pondering "AGI" (Part 3)

As discussed in the previous article, we’re designing our “AGI” in the image of man.
Truth, Reality, and Belief Systems in Intelligent Agents
The Nature of Truth and Reality
In our knowledge representation system, we make a crucial distinction between what is TRUE within a given context and what is REAL in an absolute sense. This distinction isn't merely philosophical - it forms the foundation of how our system represents and reasons about the world.
Consider the statement "Dragons exist in Game of Thrones." This statement is TRUE within the context of the Game of Thrones fictional universe, but dragons are not REAL in our physical world. However, the Game of Thrones universe itself is REAL - it exists as a created work of fiction, even though its contents are not physically real. This layered nature of truth and reality maps naturally onto our hybrid semantic-probabilistic knowledge system.
The semantic embedding space captures contextual truth - it represents how concepts relate to each other within their respective domains. When we embed the concept "dragon" in our semantic space, it might be closely related to concepts like "fantasy," "fire-breathing," and "flying," while also having strong connections to specific fictional contexts like "Game of Thrones" or "Lord of the Rings." These relationships are TRUE within their contexts, regardless of physical reality.
Meanwhile, the Markov Logic Networks handle questions of REALITY and uncertainty. Each node and relationship in our knowledge graph carries weights that represent our confidence in its physical reality or validity. These weights aren't simple binary values but rather exist on a spectrum, allowing us to represent different degrees of reality and certainty.
Belief Formation and Updating
Our system's beliefs emerge from the interaction between semantic relationships and probabilistic weights. The semantic embeddings provide the structure and context for beliefs - they tell us what things mean and how they relate to each other. The MLN weights then provide the degree of confidence or certainty in these relationships.
This dual representation allows for sophisticated belief updating through surprise minimization. When the system encounters new information, it updates both the semantic relationships and the probabilistic weights. If it observes something unexpected, this creates "surprise" - a divergence between predicted and observed reality. The system then adjusts its beliefs to minimize this surprise.
For example, if our system initially believes that "all birds can fly" with high confidence, encountering penguins creates surprise. The system must then update both its semantic understanding (learning that "flying" isn't as central to the concept of "bird" as previously thought) and its probabilistic beliefs (reducing the weight on the relationship between "bird" and "flying ability").
Priorities and Values
The interaction between truth and reality directly informs how our system develops priorities and values. The semantic embeddings help identify what concepts and relationships are relevant to a given situation, while the MLN weights help determine their importance and reliability.
Values emerge from patterns in these weights and relationships. If certain outcomes consistently lead to positive results (as measured by surprise minimization and other metrics), the system develops stronger weights for the relationships that predict or lead to those outcomes. These strengthened relationships effectively become values that guide future decision-making.
Consider how this plays out in a practical scenario: If our system consistently observes that accurate information leads to better predictions and lower surprise, it will develop a "value" for truth-seeking and accuracy. This isn't programmed explicitly but emerges from the system's drive to minimize surprise and make reliable predictions.
Similarly, priorities emerge from the interaction between semantic relevance and probabilistic importance. When making decisions, the system considers both how semantically relevant different options are to the current context and how important or reliable they are according to the MLN weights. This allows for dynamic priority setting that adapts to different contexts while maintaining consistency with the system's overall beliefs and values.
The Role of Context
Context plays a crucial role in how our system handles truth, reality, and beliefs. The semantic embedding space allows us to represent how the meaning and relevance of concepts shift across different contexts. Meanwhile, the MLN weights help us track how reliable or important different pieces of knowledge are in different situations.
This contextual awareness is essential for intelligent behavior. It allows the system to understand that while dragons aren't real in a physical sense, they're perfectly valid topics of discussion when talking about fantasy literature. It can simultaneously maintain the truth of statements within their proper contexts while understanding their relationship to physical reality.
Learning and Adaptation
Perhaps most importantly, this dual system allows for sophisticated learning and adaptation. The semantic embeddings can be updated to reflect new understandings of how concepts relate to each other, while the MLN weights can be adjusted to reflect new evidence about what is real or reliable.
This learning isn't just about accumulating facts - it's about developing a coherent worldview that balances truth in different contexts with understanding of physical reality. The system can learn new concepts and relationships while maintaining appropriate degrees of belief or skepticism about their reality or reliability.
For example, when learning about scientific theories, the system can represent both what the theories claim (semantic relationships) and how well-supported they are by evidence (MLN weights). As new evidence and experiences emerge, both components can be updated appropriately.
Implications for Decision Making
This rich representation of truth, reality, and beliefs leads to more sophisticated decision making. When faced with a choice, the system can consider:
What options are semantically relevant to the current context
How reliable or important different pieces of information are
What values or priorities have emerged from past experience
How different choices might affect future surprise and learning
The integration of semantic meaning with probabilistic reasoning allows the system to make decisions that are both contextually appropriate and well-grounded in reality. It can reason about hypotheticals while maintaining awareness of what is physically possible, and it can apply learned values while adapting to new situations.
Practical Examples
Let's explore how our semantic embedding and Markov Logic Network (MLN) system works in practice through a series of increasingly complex examples. We'll examine both memory retrieval operations and decision-making processes, showing how the system handles different types of queries and scenarios.
Basic Memory Retrieval
Let's start with a simple example: suppose our AI system needs to answer questions about transportation. When asked "What are some ways to travel between cities?", here's how the retrieval process works:
First, the semantic embedding system identifies relevant concept nodes by finding the K-nearest neighbors to "intercity travel" in the embedding space. This might return nodes like:
- Airplane (similarity: 0.89)
- Train (similarity: 0.87)
- Bus (similarity: 0.85)
- Car (similarity: 0.82)
- Bicycle (similarity: 0.45)
The MLN weights then help prioritize these options based on their practicality and reliability. Each transportation method has associated probability weights for different contexts. For instance:
- Airplane: 0.95 weight for long-distance travel
- Train: 0.88 weight for medium-distance travel
- Bus: 0.82 weight for medium-distance travel
- Car: 0.78 weight for flexible travel
- Bicycle: 0.15 weight for intercity travel
By combining semantic relevance with MLN weights, the system can provide nuanced answers that consider both relevance and practicality. It might respond: "The most practical options for intercity travel are airplanes (especially for long distances), trains, and buses. While cars offer flexibility, they may be less practical for very long distances. Bicycles, though technically possible, are rarely practical for intercity travel."
Complex Knowledge Integration
Now let's consider a more complex scenario involving both fictional and real-world knowledge. Suppose the system is asked about "dragons in different stories and cultures."
The semantic embedding space helps organize different types of dragons:
- Western dragons (fire-breathing, winged)
- Eastern dragons (serpentine, associated with wisdom)
- Modern fantasy dragons (Game of Thrones, Harry Potter)
- Historical dragon myths
- Komodo dragons (real animals)
The MLN weights capture different types of truth and reality:
- Komodo dragons: 1.0 weight for physical existence
- Historical dragon myths: 0.95 weight for cultural existence
- Game of Thrones dragons: 0.98 weight for fictional existence, 0.0 weight for physical existence
- General dragon concept: 0.9 weight for cultural significance, 0.0 weight for physical existence
When traversing the knowledge graph, the system can follow different types of relationships:
- Physical relationships (what actually exists)
- Fictional relationships (what exists in stories)
- Cultural relationships (what exists in human belief systems)
- Metaphorical relationships (symbolic meanings)
Each type of relationship carries its own MLN weights, allowing the system to reason appropriately about different contexts while maintaining clear distinctions between reality and fiction.
Decision-Making Scenarios
Let's examine how the system handles decision-making in a practical scenario: helping a user plan a trip to Japan.
The semantic embedding space helps identify relevant concepts and considerations:
- Transportation options
- Accommodation choices
- Cultural sites
- Language barriers
- Seasonal considerations
- Budget constraints
The MLN weights help evaluate the reliability and importance of different pieces of information:
- Official travel guidelines: 0.95 weight
- Recent user reviews: 0.85 weight
- Personal travel blogs: 0.75 weight
- Old guidebook information: 0.60 weight
- Anecdotal advice: 0.50 weight
The system then uses these weights to prioritize information and make recommendations. For instance, when considering cherry blossom viewing:
Semantic relationships identify:
- Peak bloom times
- Popular viewing locations
- Alternative activities
- Crowd considerations
- Weather patterns
MLN weights help evaluate:
- Reliability of historical bloom data: 0.85
- Accuracy of current year predictions: 0.70
- Crowding pattern predictions: 0.80
- Weather forecasts: 0.75
The system can then make nuanced recommendations like: "Based on historical data (0.85 confidence) and current predictions (0.70 confidence), plan to visit Tokyo between March 25-April 5 for cherry blossoms. However, consider Kyoto for April 5-15 as a backup plan, as variations in timing are common."
Emergency Response Scenario
Let's examine a high-stakes scenario where rapid, accurate decision-making is crucial: responding to a medical emergency.
The semantic embedding space quickly identifies relevant concepts:
- Symptoms and their relationships
- Possible conditions
- Treatment options
- Emergency procedures
- Medical facilities
- Response protocols
The MLN weights help prioritize different factors:
- Life-threatening symptoms: 0.98 weight
- Emergency response protocols: 0.95 weight
- Standard first aid procedures: 0.90 weight
- Personal medical history: 0.85 weight
- General medical knowledge: 0.80 weight
- Alternative treatments: 0.40 weight
The system can traverse the knowledge graph, using both semantic relationships and MLN weights to:
1. Identify the most critical symptoms
2. Match them to possible conditions
3. Determine appropriate immediate responses
4. Identify the nearest suitable medical facilities
5. Generate step-by-step instructions for first responders
The combined system allows for both rapid retrieval of critical information and careful weighing of different factors in the decision-making process.
These examples are intended to demonstrate how the semantic-MLN system combines flexible knowledge representation with probabilistic reasoning to handle a wide range of real-world scenarios. The semantic embeddings provide rich, contextual understanding, while the MLN weights enable appropriate prioritization and decision-making. Together, they create a system that can both retrieve relevant information and make nuanced decisions while maintaining appropriate distinctions between different types of knowledge and truth.

Merry Christmas!
